
What to make of OpenAI’s latest GPT-5 chatbot? Let’s just say the reception from users has been sufficiently mixed to have OpenAI head honcho Sam Altman posting apologetically on X. And more than once. But one thing we can say for sure, the charts in the launch video were a bizarre mess that OpenAI has since attempted to tidy up, to mixed avail.
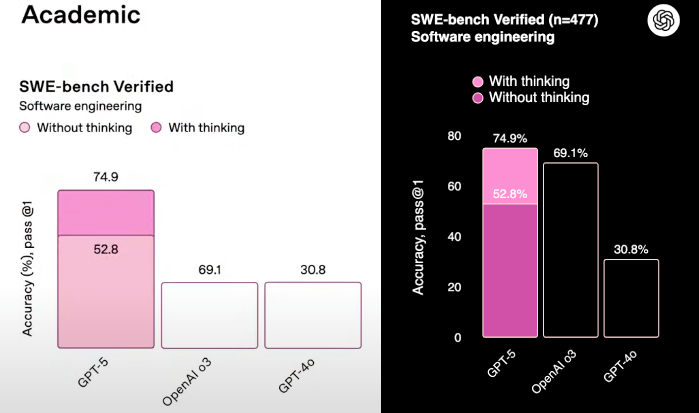
Most obviously, the claimed SWE-bench performance of GPT-5 versus older model shown on launch day was badly botched. The chart showed accuracy figures of 74.9% for ChatGPT 5, 69.1% for OpenAi o3 and 30.8% for GPT-4o.

Problem is, the bar graph heights were exactly the same for the latter two, giving the at-a-glance impression of total dominance for GPT-5 when in fact it is only marginally superior to OpenAI o3.
It’s a basic enough mistake that you have to wonder whether OpenAI used, well, GPT-5 itself make the charts and couldn’t be bothered to proof them. Later on in the video there’s another graph showing, not a little ironically, the deception rate of GPT-5. In this chart, it shows the bar graphs for GPT-5 and OpenAI o3.
GPT-5 scores a “coding deception” rate of 50%, OpenAI o3’s is 47.4%. But the bar for OpenAI o3 is rendered roughly three times higher than that of GPT-5. Now, you could recognise that a lower deception rate is better and make some kind of convoluted argument for therefore making OpenAI o3’s bar higher.

Apart from the fact that this approach still doesn’t account for the large discrepancy in bar height, the problem is that on the same slide OpenAI also shows stats for “CharXiv missing image”. And here the bars are accurately proportional to the percentage results, with the 9% for GPT-5 a tiny fraction of the height of the 86.7% for OpenAI o3.
Another wonky chart cooked up by AI? Some kind of subtle satire? Just lazy, sloppy work? The usual adage probably applies, so assuming conspiracy where mere incompetence will suffice is probably unjustified. But it certainly implies a level of complacency that squares with the overall sense of entitlement and lack of rigour and accountability that surrounds the AI industry at large.
However, while the bar height in the SWE-bench chart has also been corrected, OpenAI added a further disclaimer, pointing out that the figures were achieved using 477 tasks within the SWE-bench suite, not the full 500.
When we compare directly to Anthropic’s Claude Opus 4.1, which has achieved a score of 74.5% on SWE-bench Verified, GPT-5 appears to score slightly better at 74.9%. But where are these 23 missing problems? What are they? pic.twitter.com/F8BSZnxLZtAugust 11, 2025
That has lead some observers to question whether a few inconvenient tasks were left out in order to allow GPT-5 to hit 74.9% and thus edge marginally ahead of the 74.5% score racked up by Anthropic’s Claude Opus 4.1 model. Indeed, this raised the eyebrow of none other than Elon Musk, too.
Meanwhile, original launch video with the messed up charts is still there on OpenAI’s YouTube channel, implying OpenAI isn’t all that bothered. Whatever is going on, exactly, it’s all fairly unsightly. At best it’s unbecoming of an organisation that supposedly produces artificial “intelligence.” At worst, it’s thoroughly unnerving if managing the dangers AI and all our safety depends on these people.

Best gaming PC 2025